
转载请注明出处!
仅用于学习和技术讨论,严禁用于商业用途!
所有源码与编译好的刷题APP见github仓库:keggin-CHN/njfu_grinding
抓包部分
1.单个试题的选项与答案的抓取
在校园网环境下打开马院答题系统,这里以马原系统为例(http://202.119.208.106),进入之后随便点击一个正式考试,这时你的网址会变成http://202.119.208.106/talk/ExamCaseGeneral.jspx?case_id=ee920c4c-d2c8-4623-a40e-717ceec16a80,
这个网址中ExamCaseGeneral.jspx是考试页面的特征url,更一般地提交以后ExamCaseGeneral.jspx会变成ExamCaseReportGeneral.jspx,这是报告页面的特征url。ee920c4c-d2c8-4623-a40e-717ceec16a80则是考试中心分配给这张试卷的唯一UUID。
如果将report界面的网址(例如:http://202.119.208.106/talk/ExamCaseReportGeneral.jspx?case_id=ee920c4c-d2c8-4623-a40e-717ceec16a80)手动删除Report,
并回车http://202.119.208.106/talk/ExamCaseGeneral.jspx?case_id=ee920c4c-d2c8-4623-a40e-717ceec16a80,你会发现自己又回到了答题界面,并且试卷结构没有改变。
因此我们可以直接提交一张白卷,进入report页面,将这套试卷的答案进行保存。此功能可以由一个简单的javascript脚本搭配Tampermonkey插件实现,见github仓库:https://github.com/keggin-CHN/njfu-exam
实现方法:(使用Reqable或者打开F12开发者模式)
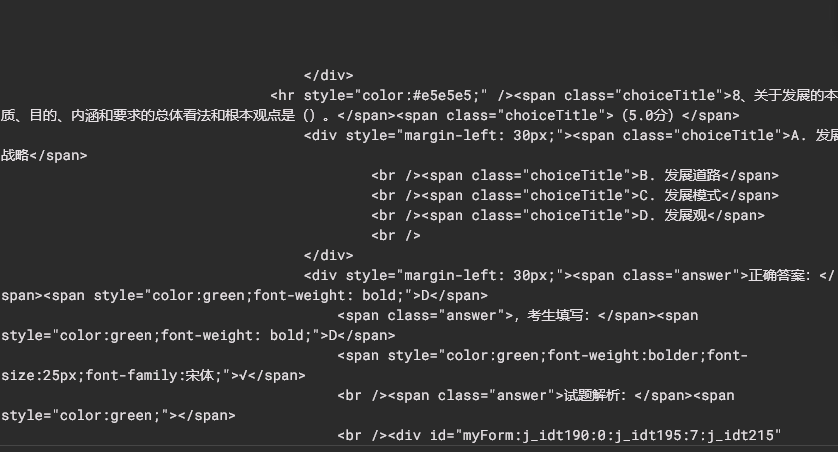
在解析出来的HTML里面包含了所有题目的题干、选项、作答情况和正确答案,即可后期编写程序对这个html页面进行爬取。
2.题库接口的抓包
由于马院答题系统的题库是发生在服务器端的,其API无法查询到,但是我们可以通过找到再次考试的接口,实现绕过答题总次数的限制,该接口的抓包如下:
在系统首页(特征url为talk/ExaminationList.jspx?type=1)的页面点击正式考试
在F12-NETWORK或者小黄鸟Reqable中找到http://202.119.208.106/talk/ExaminationList.jspx?type=1的请求包,搜索如下关键字:servlet/pc/ExamCaseController,会查找到多个结果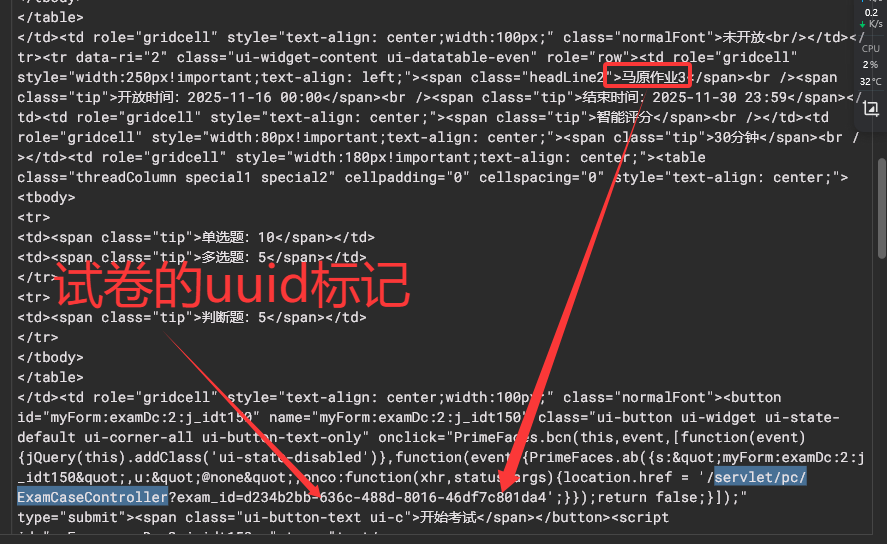
如图这里是马原作业3的抓包结果,则马原平时作业3对应的uuid就是d234b2bb-636c-488d-8016-46df7c801da4,
这时把浏览器的网址进行修改:将http://202.119.208.106/xxxxxxxxxxxxxxxxxxxx(你当前所在的子页面)改成
http://202.119.208.106/servlet/pc/ExamCaseController?exam_id=d234b2bb-636c-488d-8016-46df7c801da4,
你会发现自己进入了马原平时作业3的考试界面,并且再这个过程中URL发生了跳转,变成了http://202.119.208.106/talk/ExamCaseGeneralStep.jspx?exam_id=d234b2bb-636c-488d-8016-46df7c801da4,
这是由于在你访问ExamCaseController页面时,考试中心服务器对你的请求进行了转发,给了你一张对应的卷子,同时当你再次输入这个网址http://202.119.208.106/servlet/pc/ExamCaseController?exam_id=d234b2bb-636c-488d-8016-46df7c801da4,
你会发现卷子变成了另一套!并且我们是通过直接向考试中心服务器发送请求包的,而没有中间途径,因此跨越了考试次数3次(模拟考试5次)的限制。
说到这你应该就明白了题库的爬虫原理。
爬虫原理
爬虫所使用的python脚本见github仓库:njfu_grinding/爬虫/scraper.py at main · keggin-CHN/njfu_grinding
使用此脚本需要修改如下变量:
# --- 宏定义 ---
USERNAME = ""
PASSWORD = ""
EXAM_URL = "http://202.119.208.57/servlet/pc/ExamCaseController?exam_id=0f770163-73fe-4328-861a-dfd15ce26726"
LOOP_COUNT = 50
BASE_URL = "http://202.119.208.57"
DEBUG = False
PARALLEL_WORKERS = 6
# --- 宏定义结束 ---Selenium

EXAM_URL就是上述抓包的链接,
LOOP_COUNT是循环抓包的次数,调的越高爬虫效果越好,但是时间更长!
BASE_URL是对应马院的服务器IP,例如马原是202.119.208.106
Debug = True 为是否启用调试模式(当有些页面的元素发生变化而导致脚本需要变化时)
PARALLEL_WORKERS = 6 为多线程并行,使用6即可。
爬虫结果如下所示:
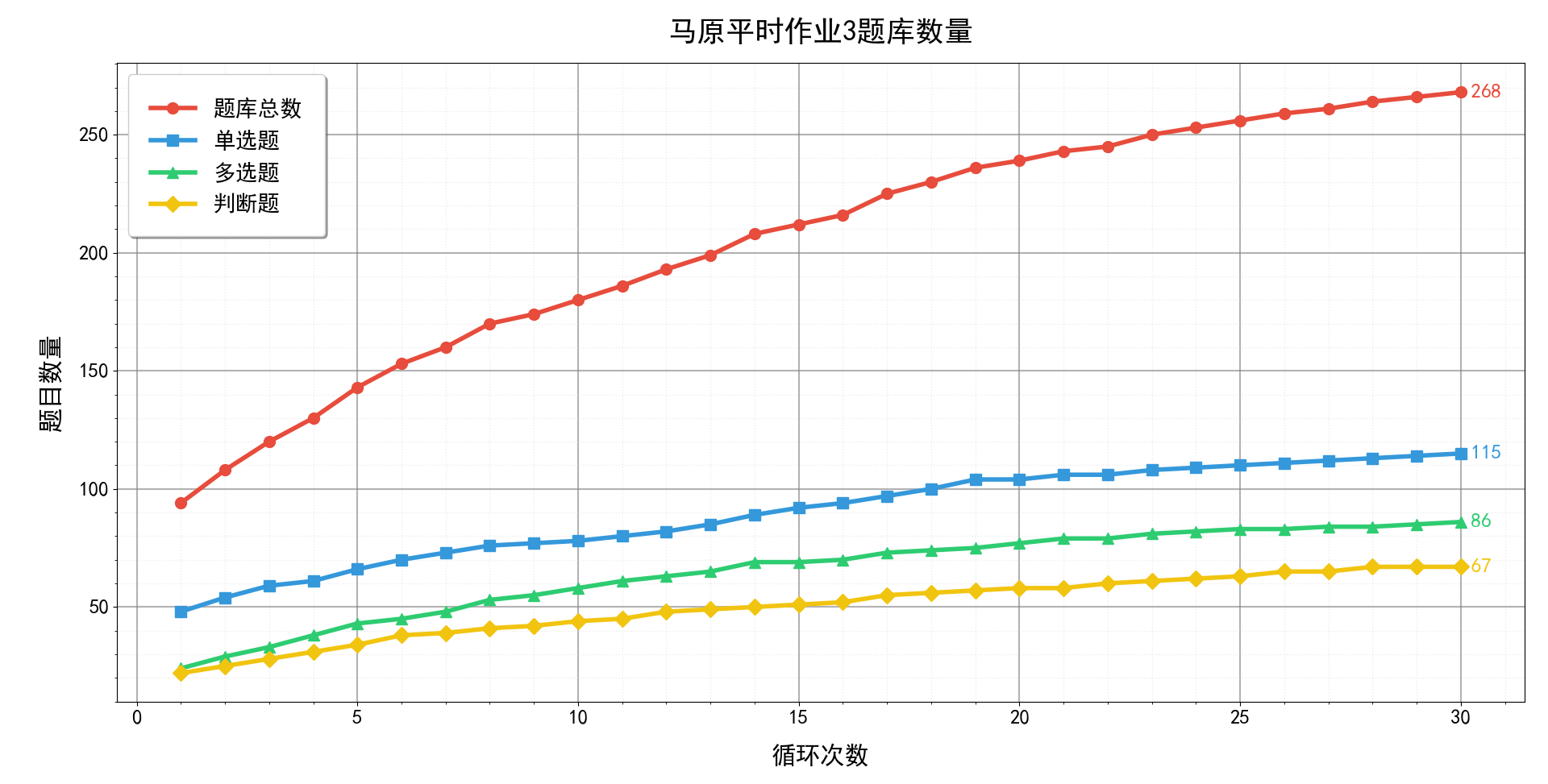
最后再工作的文件夹下会得到一个json格式的文件,此为爬虫的题库,导入到APP中即可食用!

